The Twelve-Factor App

The Twelve-Factor App es una metodología (según su web, aunque la veo más como un conjunto de best practices) aplicable al desarrollo de aplicaciones y servicios Web basados en el modelo de software as a service (SaaS).
Los motivos por los que nos puede interesar conocer y aplicar una guía de buenas prácticas como esta son muchos y variados:
- Para tomarlo como un punto de partida sobre el que ir evolucionando en los procedimientos o técnicas de un equipo u organización
- Por conocer cómo hacen otros compañeros de profesión las cosas y aprender de su experiencia
- Por conocer las tendencias (que en estas cosas hay mucho valor pero también mucha moda)
- Por establecer un punto común de partida en el equipo consensuado por todos del que luego ir evolucionando
- Por ver diferentes opciones y tener juicio crítico para evaluarlas
En todo caso, la adopción, si conviene, debemos hacerla de una manera práctica y con juicio crítico. No es necesario implementarla al completo, solo aquellas partes que nos interesen o hacerlo de manera progresiva. También puede servir como un punto de partida del que luego iterar según nos dicte el contexto o nuestras necesidades a algo más apropiado para nosotros, que puede ser más o menos cercano a lo que nos cuenta la metodología. Y teniendo total libertad para decidir qué partes se adoptan y cuáles no o cuáles se hacen de una manera diferente, según lo que nos dicte el sentido común y el buen criterio. En todo caso no soy partidario de aplicarlas de manera dogmática, estricta y completa; porque eso puede convertir la herramienta en un lastre, lo que termina desacreditándola y haciéndole perder gran parte de su valor.
La metodología Twelve-Factor App está orientada a aplicaciones Web. No por su naturaleza Web en sí, sino por el modelo de negocio o explotación al que está orientado: software-as-a-service (SaaS). La gran peculiaridad de este modelo, frente a otros de software, es que solo se explota una instancia y una versión de la aplicación (servicio realmente) por lo que:
- no existe fragmentación
- su operación es única, sencilla y centralizada
- su rollout es más sencillo y rápido
A su vez, por su propia naturaleza Web, son soluciones más escalables, accesibles, más independientes de plataforma y de menor coste.
La metodología está compuesta por 12 capítulos o factores. En algunos de ellos se nota esta orientación a SaaS, ya que serían difícilmente aplicables a otros modelos. Esto es relevante porque, según nos alejemos del modelo SaaS, su idoneidad es más cuestionable y podrían plantearse alternativas mejores.
TLDR ;-P
- I. Base de código: Existe un solo repositorio de código y muchos despliegues o instancias
- II. Dependencias: Las dependencias se declaran explícitamente y se gestionan aisladamente
- III. Parametrización: La parametrización de cada entorno se gestiona independientemente y de manera aislada al código
- IV. Backing services: Los backing services son recursos asociados a la aplicación pero desacoplados de su ciclo de vida
- V. Construye, lanza y ejecuta: Las fases de construcción, lanzamiento y ejecución están aisladas y diferenciadas entre sí. La release lo conforman el código y la parametrización conjuntos
- VI. Procesos o instancias concurrentes: La aplicación la conforman varios procesos concurrentes sin estado (shared-nothing architecture). El estado es un recurso compartido por todos los procesos
- VII. Vinculación al puerto: Los servicios se publicitan mediante puertos. El descubrimiento de servicios se hace vía puerto, a nivel de red
- VIII. Concurrencia: La aplicación escala fácil, sencilla y rápidamente a nivel de proceso
- IX. Desechabilidad: Maximiza la resiliencia facilitando la creación y destrucción de procesos, haciéndolos contingentes y desechables
- X. Igualdad de los entornos de desarrollo y producción: Los entornos de desarrollo y producción deben ser lo más parecidos posible
- XI. Trazas: Trata las trazas de aplicación como flujos de datos. Homogeneiza su recolección y tratamiento
- XII. Procesos de administración y operativa: Los procesos, tareas y componentes complementarios al core de la aplicación también deben seguir estas prácticas al ser parte del juego de procesos
I. Base de código
La relación entre código y aplicación es uno a uno, única. Sólo existe un repositorio de código para toda la aplicación.
Aún pudiendo existir diferentes instancias o despliegues de la misma aplicación, esta proviene siempre de un único repositorio de código (o varios solo si estos pueden vincularse a mismo commit o transacción).
Las instancias pueden ser de entre sí versiones distintas del mismo código y repositorio: producción, validación, integración, local del desarrollador…
A su vez, si el mismo código es utilizado en más de una aplicación, debe tratarse como una librería, como una dependencia, y no como una aplicación. Es la aplicación donde se integra dicha librería de código compartido a la que se le aplica esta metodología.
II. Dependencias
Las dependencias se declaran de manera completa (todas y cada una), unívoca (con su versión específica) y explícita (existe un mecanismo que las enumera y gestiona).
Todas las dependencias se empaquetan o despliegan con la propia aplicación de manera aislada al resto de los componentes que pueden existir con anterioridad en el mismo sistema (como se hace combinando virtualenv y pip en Python). La aplicación no debe depender de ninguna librería del sistema y entorno, si no es del entorno exclusivo de ejecución de la aplicación (por ejemplo, no se debe enlazar a una dependencia global de npm o de una utilidad existente en el sistema operativo).
Sin embargo, existen excepciones como drivers, software base o sistema operativo o la misma plataforma o framework de ejecución que son requisitos preliminares y que no pueden gestionarse de manera aislada. Esto no quita que deban enumerarse e identificarse entre las dependencias.
III. Parametrización
La parametrización es todo aquel valor, parámetro o variable que depende únicamente del entorno o instancia donde se ejecuta la aplicación. Las variables propias de la aplicación que no dependen del entorno o contexto (por ejemplo, la definición del contexto IoC de Spring) no se considera parametrización.
La parametrización nunca va incluida en el código y está completamente separada de este. Como prueba de esta condición se propone que evaluemos si podríamos ofrecer el código de manera abierta sin que se detallase ningún detalle que distinga los entornos o instancias.
La metodología recomiendo el uso de variables de entorno por ser agnóstico del entorno y lenguaje de programación. Yo particularmente, no estoy de acuerdo, puesto que algunas parametrizaciones pueden ser muy tediosas de configurar así, y porque formatos como JSON, XML o YAML son ampliamente soportados.
Las parametrizaciones de los entornos deben ser «ortogonales» o independientes entre sí. No deben estar agrupadas o asociadas (por ejemplo, en el mismo fichero), deben estar aisladas entre sí.
IV. Backing services
No he encontrado una traducción adecuada para backing service. Quizás servicio de apoyo o auxiliar, pero como tampoco me ha gustado he decido utilizar el término sin traducir.
La metodología denomina backing service a todo componente accesible mediante red. He añadido alguna matización en las notas al final del artículo. Por simplificar, yo considero backing service todo componente que no es parte de la release, con ciclo de vida independiente al de nuestra aplicación y con una versión o interface por general estático, que no cambia.
Ejemplos de backend services pueden ser una base de datos MySQL, una cola Kafka, el API de Google Maps o Facebook o el servicio de trazas AWS Cloudwatch.
La principal diferencia con las dependencias es que no forman parte de proceso de release por un lado, y que pueden intercambiarse por distintas instancias o incluso versiones durante el despliegue (generalmente mediante un parámetro) o en tiempo de ejecución, sin que por eso afecte a la funcionalidad o estabilidad de la aplicación.
Los backing services deben ser totalmente desacoplados y aislados de la aplicación. Son intercambiables. Se comportan como recursos enlazados, anexos o adjuntos a la aplicación mediante parametrización generalmente. Tienen un ciclo de vida completamente independiente al de la aplicación. Todo lo contrario que las dependencias que eran parte del build y release.
En las arquitecturas basadas en recursos efímeros como puede ser la basada en containers. Los componentes no efímeros, los servicios de persistencia o almacenamiento por ejemplo, pueden considerarse backing services, porque tienen un ciclo de vida alternativo al del resto de los componentes y pueden sustituirse o desacoplarse de manera independiente.
V. Construye, lanza y ejecuta
El objetivo de la base de código es el despliegue en un entorno productivo.
Este proceso se compone de 3 fases diferenciadas: construcción, lanzamiento y ejecución de la instancia o entorno.
Construcción
Construcción es el proceso en el que se toma el código de un punto específico o versión, se recolectan las dependencias y se generan los binarios y recursos que forman el producto o build.
La construcción de la misma versión de código siempre producirá el mismo build. Las dependencias, la configuración y versiones de las herramientas utilizadas durante la construcción; así como los recursos no compilados son parte de la propia versión, de la base de código. La construcción al ser un proceso determinista siempre tendrá el mismo resultado.
Lanzamiento
El lanzamiento es la combinación del build del proceso de construcción junto con la configuración propia del entorno o instancia, para crear el lanzamiento o release.
La configuración del entorno es la parametrización propia del entorno, aquellos grados de libertad que el código permite configurar en la instancia.
La configuración no forma parte de la base de código ni del build, pero sí de la release.
La release está vinculada entonces a un momento puntual en el tiempo del código y con una parametrización del entorno en particular. Es el estado momentáneo de la instancia o servicio. La release es siempre etiquetada siguiendo una nomenclatura descriptiva de ambos componentes, la versión del software y de la parametrización del entorno.
Que parametrización y código se congelen en un punto común, como es la release, tiene sentido puesto que el código puede comportarse entre versiones de manera distinta para un mismo parámetro o porque una parametrización distinta cambia el comportamiento del mismo código. Código y configuración son dos grados de libertad que quedan vinculados en la release.
La release es el estado concreto que se ejecuta en una instancia y en un momento dados. Si queremos replicar el estado software de una instancia, para replicar un bug en un entorno alternativo por ejemplo, tendremos que desplegar esa release en el entorno de desarrollo del bugfix.

Ejecución
Lo que se despliega en la instancia o múltiples instancias del entorno es siempre la release. Tanto si el proceso es manual o como si es automatizado o si existen mecanismos de autoescalado en múltiples instancias, en todas ellas se va a desplegar y ejecutar siempre la misma release.
Mientras que la generación de build y release son procesos originados solo por el cambio del código, la ejecución de la release se produce en muchas ocasiones: en cada escalado, en cada reinicio, en cada proceso batch, de manera constante en arquitecturas efímeras…
Otra gran ventaja de este modelo es que los rollback de los despliegues son mucho más directos y sencillos al contener la release tanto build como configuración.
Existen casos en los que en un mismo entorno pueden haber diferentes releases desplegadas y ejecutando a la vez, como pueden ser los despliegues de pruebas A/B o los procedimientos de despliegue Blue/Green.
VI. Procesos o instancias concurrentes
La aplicación se ejecuta como un conjunto de procesos aislados sin estado y con una arquitectura o filosofía shared-nothing.
Si la aplicación debe persistir su estado o transacciones lo hace en un backing service dedicado como puede ser una base de datos. El estado solo se persiste ahí. Esto permite gestionar instancias de manera independiente con el estado y aporta mucha mayor resiliencia.
La arquitectura shared-nothing se basa en el hecho de que cualquier transacción debería poder ser servida por cualquier nodo o parte replicada de la aplicación, por cualquier proceso. Todos los procesos tienen acceso a la misma información mediante el backing service que hace de capa de persistencia. Puesto que toda la información es compartida y modificable por los procesos, no se recomienda el uso de cachés que pueden ocultar cambios de estado posteriores o que pueden requerir complejos refrescos de la información (patrón de saga).
Mecanismos del tipo sticky session que vinculan la sesión del cliente o usuario con unos procesos determinados no son recomendables tampoco por estos criterios de aislamiento o de procesos sin estado. La información de sesión es preferible que se almacene en una caché de memoria compartida o similar (memcache o Redis por ejemplo).
VII. Vinculación al puerto
Las aplicaciones Web suelen correr sobre una plataforma o contenedor Web que abstrae todo el networking y lógica de los protocolos de red. En esencia, el interfaz último es el puerto de red del servicio. En los ejemplos que menciono es HTTP, pero puede ser cualquier otro protocolo.
Se podría considerar que servidores Web como Tomcat o un módulo de Apache son una base independiente necesaria, como si de un backing service se tratase. La metodología sugiere lo contrario, que se traten como dependencias propias de la aplicación, que se despliegan con la propia aplicación y forman parte de la release. Se sugiere a modo de ejemplo embeber servidores como Jetty, Thin, Tornado, en lugar de las opciones independientes.
El fin es que el interfaz último sea este puerto/servicio de red, que sea ese el punto de acceso y referencia a la aplicación. La presentación pública del servicio no es más que un enrutamiento a ese punto de acceso, sea a nivel de red (mediante DNS) o a nivel de protocolo (mapeado de URLs).
Por otro lado, lo que se persigue también es que la unidad de despliegue sea una caja negra hasta ese nivel de red, que dicha aplicación sea autocontenida e independiente. Con las siguientes ventajas
- Los entornos de desarrollos y productivos son mucho más parecidos al conservar los mismos servidores y configuraciones
- Los modelos de concurrencia u orientados a procesos, como se describen en los apartados VI y VIII, se simplifican
- Cualquier aplicación puede ser un backing service de manera inmediata, siendo referenciada a su puerto de servicio, para otra aplicación
- Puesto que el interfaz es el servicio de red, la sustitución de estos servicios Web embebidos es transparente, como si de una dependencia se tratase
- Al ser una unidad autocontenida, los requisitos necesarios para el entorno que vaya a correr los procesos son mucho menos restrictivos y la aplicación puede desplegarse en una variedad mayor de entornos
VIII. Concurrencia
Para facilitar la concurrencia y el escalado de la aplicación, se considera el proceso como la unidad básica de la aplicación.
El modelo recomendado es el de los procesos UNIX que corren demonizados. La gestión del proceso no se vincula a ningún mecanismo en particular, sino que se deja en mano de los mecanismos más generales y comunes del sistema donde corre la aplicación (como systemd).
El diseño de la aplicación implica considerar qué tipos de procesos diferentes existen para cada diferente necesidad (web, batch, stream de eventos…). La naturaleza de cada proceso se adapta a la necesidad que cubre. La instancia de la aplicación tendrá entonces un número de procesos concurrentes corriendo para cada tipo de tipo en particular. El conjunto de tipos de procesos y su número es lo que denomina el juego de procesos.
La operación de la plataforma conlleva la concurrencia y replicación de esos tipos de procesos para cubrir la demanda o carga de cada uno. Este modelo permite que el escalado sea muy sencillo y favorece la filosofía share-nothing. Añadir un nuevo tipo es muy sencillo y podría hacerse sin afectar al resto. Escalar un tipo añadiendo más procesos concurrentes, que pueden estar en la misma máquina física o no, también es sencillo e independiente a los existentes.
IX. Desechabilidad
Los procesos deben ser fácil y rápidos de lanzar y de terminar, y el impacto en la operación o en el servicio de estos cambios debe ser mínimo. El proceso es desechable. El objetivo es que las partes que componen el servicio sean fácilmente y rápidamente invocables y sustituibles.
De esta manera, el escalado del servicio replicando los procesos es muy sencillo. Si la replicación de estos procesos es ágil y sencilla, el escalado también lo es.
De igual manera aplicar cambios en la configuración, o incluso hacer la marcha atrás de estos cambios en caso de error, es también muy rápido y sencillo; tan solo hay que sustituir unos procesos por otros con la nueva configuración. Si la facilidad y rapidez con que se terminan los procesos y se comienzan los nuevos es alta, el impacto y el riesgo en el servicio de los cambios será menor.
Los procesos deben de terminarse de una manera sencilla, elegante y estable. Desde el momento que recibe la señal de finalización, el servicio o recepción de peticiones debe pararse y la petición en curso debe finalizarse completa y correctamente. Si hablamos de procesos encolados, la petición en curso debe devolverse a la cola, por ejemplo.
Dada esta naturaleza desechable, el impacto de una terminación no controlada o no limpia de un proceso debe ser también controlado o al menos mitigado y acotado.
El resultado de los procesos también debe ser desechable, bien porque forma parte de algún tipo de transacción (de tal manera que pueda deshacerse) o bien porque es idempotente, para que su reinvocación no modifique erróneamente el resultado.
X. Igualdad de los entornos de desarrollo y producción
Toda la metodología está orientada a un entorno de despliegue/integración continuos en los que el gap tanto temporal como técnico entre los entornos es mínimo:
- el tiempo entre que una característica está disponible para producción (definición de done done) y su despliegue es muy pequeño, de horas incluso
- las personas involucradas en ambos entornos son las mismas (DevOps) o al menos, no existe desentendimiento por parte de unos en el entorno de otros
- los componentes, backend services y dependencias son los mismos en todos los entornos
La metodología hace mucho hincapié en no sustituir componentes por otros sucedáneos o lightweight, sino usar los mismos elementos software. Hoy en día esto es relativamente sencillo mediante las tecnologías de container o de cloud, que permiten desplegar el mismo componente pero con dimensionamientos apropiados para cada entorno.
Los entornos pueden ser efímeros, de tal manera que sean creados desde cero por completo cada vez que se despliegan, que no se actualicen conservando elementos de la versión anterior. Esto evita que haya deriva en los entornos (que tengan cambios no documentados, que se degraden con el tiempo…) y fuerza que los entornos siempre sean iguales en producción y desarrollo. Por supuesto, los componentes o backend services responsables de la persistencia de datos o del balanceo de carga no pueden ser efímeros, ya que impactaría en la integridad de los datos y la disponibilidad del servicio respectivamente.
XI. Trazas
Todos y cada uno de los procesos de la aplicación deben producir logs o trazas que reflejen su estado y procesamiento. Estas trazas deben interpretarse como flujos o streams de eventos ordenados.
Habitualmente esos flujos son gestionados por cada proceso o componente de manera independiente, enviándolos a la consola de salida, a un fichero o un colector syslog, por ejemplo. La metodología propone que los flujos de logs de manera general en todos los procesos se manden a la consola de salida estándar y sea el propio entorno el que recoja estos flujos y los gestione adecuadamente.
Es el entorno o el proceso de despliegue del entorno el que decide cómo recolectar y gestionar todos los flujos de logs para cada uno de los componentes.
Estos flujos pueden agregarse en colectores de logs, como puede ser Devo, que permitan:
- Almacenar y agrupar los logs de todas las fuentes durante el tiempo necesario
- Analizar eventos y transacciones y su flujo o procesamiento a través en los componentes
- Correlar eventos y condiciones para detectar anomalías o situaciones específicas
- Agregar la información para mostrar gráficos, dashboards o vistas agregadas
XII. Procesos de administración y operativa
Además de los procesos online que ofrecen el servicio core de la aplicación existen otros procesos que corren en el entorno y que son también fundamentales:
- Procesos batch periódicos corriendo en background
- Operaciones o procedimientos de gestión específicos
- Tareas de procesamiento propias del despliegue como son migraciones o verificaciones de integridad
- Procesos de copia de respaldo o de soporte
Todos y cada uno de estos procesos complementarios:
- corren en el mismo entorno
- pertenecen a la misma base de código o versión
- se prueban y validan en el mismo proceso y a la vez que el resto del código
- forman parte de la misma configuración, release y proceso de generación de la aplicación
- forman parte del mismo proceso de despliegue
Todas las consideraciones tenidas en cuenta en las secciones anteriores deben también hacerse para estos procesos complementarios, como son la concurrencia, aislamiento de procesos, dependencias, tolerancia al error, traza…
Notas personales
Dependencias vs backing services
La metodología distingue dos términos, dependencias y backing services, y hace un tratamiento y recomendaciones muy distinto de ellos.
En la metodología considera backing service todo aquel servicio que es accesible mediante conectividad de red, pero no tiene por qué ser necesariamente así: un servicio local de disco (como puede ser EBS de AWS) es accesible de manera local, no de red (al menos desde el punto de vista de la aplicación) y en mi opinión es claramente un backing service y no una dependencia.
Por otro lado, las dependencias son consideradas librerías generalmente. Sin embargo, es posible encontrarse librerías o plataformas, que son más propias del entorno o contexto de ejecución o despliegue que de la propia aplicación. Por ejemplo, las librerías de ejecución de Node o Python disponibles en los contextos de ejecución de las Lambda de AWS o Function de Azure, son dependencias del código. Pero el modo en que vamos a poder gestionarlas es más un backing service que una dependencias, y aún así es discutible, porque no podemos cambiar una por otra de manera sencilla.
Puesto que las recomendaciones para una y otra son tan distintas, creo importante añadir otros criterios para distinguirlas. Estos son de cosecha propia:
- Todo servicio, generalmente otro SaaS, que tenga un ciclo de vida diferenciado del de nuestra aplicación, sea propio o de un tercero, es claramente un backing service.
- Las librerías del sistema o de plataforma, propias del contexto de ejecución o despliegue de la aplicación, pueden considerarse también un backing service.
- Los elementos que vienen más impuestos por el contexto de ejecución o despliegue que por las propias funcionalidades de la aplicación, suelen ser backing services.
- El código compilado durante el proceso de build y empaquetado durante el proceso de release, es dependencia.
- Los elementos que se integran o asocian a la aplicación mediante parametrización, es muy posible que sean backing services.
- Las dependencias integradas en tiempo de ejecución, como puede ser con Spring a través de IoC, pueden considerarse también backing service. La dependencia como tal, es el interfaz compilado. La librería cargada y enlazada en tiempo de ejecución podría ser un backing service.
Los backing service también tienen versionados y evoluciones con diversos criterios de compatibilidad. Tiene sentido que estas versiones sean menos dinámicas que las de las dependencias, pero no por ello pueden ignorarse. Por ejemplo, los servicios en la nube, como Google Maps, evolucionan y modifican sus interfaces. Es por ello también importante etiquetar o gestionar estas versiones.
Releases por entorno vs releases por versión del código
Uno de los aspectos que más sorprende de esta metodología es que la release contenga siempre la configuración del entorno donde se pretenda desplegar y que el despliegue sea un todo, no la instalación de un software en un primer paso y su parametrización posterior.
La principal ventaja de esta consideración es que el componente probado en los sucesivos entornos de validación, así como en las pruebas de integración de los mismo, es mucho más parecido al entorno final al contener la parametrización. Además el conjunto de lo desplegado es más compacto, unitario y tiene menos posibles puntos de error, al ser todo uno.
Ahora bien, cuando el conjunto de instancias o entornos a mantener es limitado esto es factible. Pero cuando tenemos un conjunto de instancias muy grande o cuando, sencillamente, no están bajo nuestro control, porque son despliegues en manos de terceros por ejemplo; esto es complicado.
Esta consideración es así porque la metodología es aplicable al modelo de SaS y no al de producto o software en propiedad. En estos casos cada instancia está siempre bajo el ciclo de vida del proveedor de extremo a extremo y el conjunto de instancias que dan el servicio es muy controlado y las releases gestionadas reducido (si bien en número de instancias puede ser enorme, en configuración son clones entre sí y comparten todas la misma release).
En la modalidad de software en propiedad, la parametrización es gestionada por el propietario de la instancia que no suele ser el proveedor de software. Por este motivo la release contiene solo el build y no incluye parametrización ninguna.
Zipkin
Zipkin es un gestor de traza o de log distribuido. Es muy apropiado para entornos en los que los componentes se encuentran separados en diferentes componentes de red o en entornos de ejecución distintos, como pueden ser las arquitecturas de microservicios.
La información de traza es recogida por diferentes librerías de Zipkin que añaden «instrumentación» a nuestro componente software. Estas librerías se encuentran disponibles para C#, Go, Java, Javascript, Ruby y Scala (todas estas soportadas por el propio proyecto OpenZipkin, aunque la comunidad aporta muchas más). Estas librerías se encargan de recoger la información de traza en cada operación y añadir la mínima información de identificación que permita correlar las trazas en cada componente de nuestro sistema y ver la operación como un todo, como una única traza de la misma pasando por cada uno de los componentes.
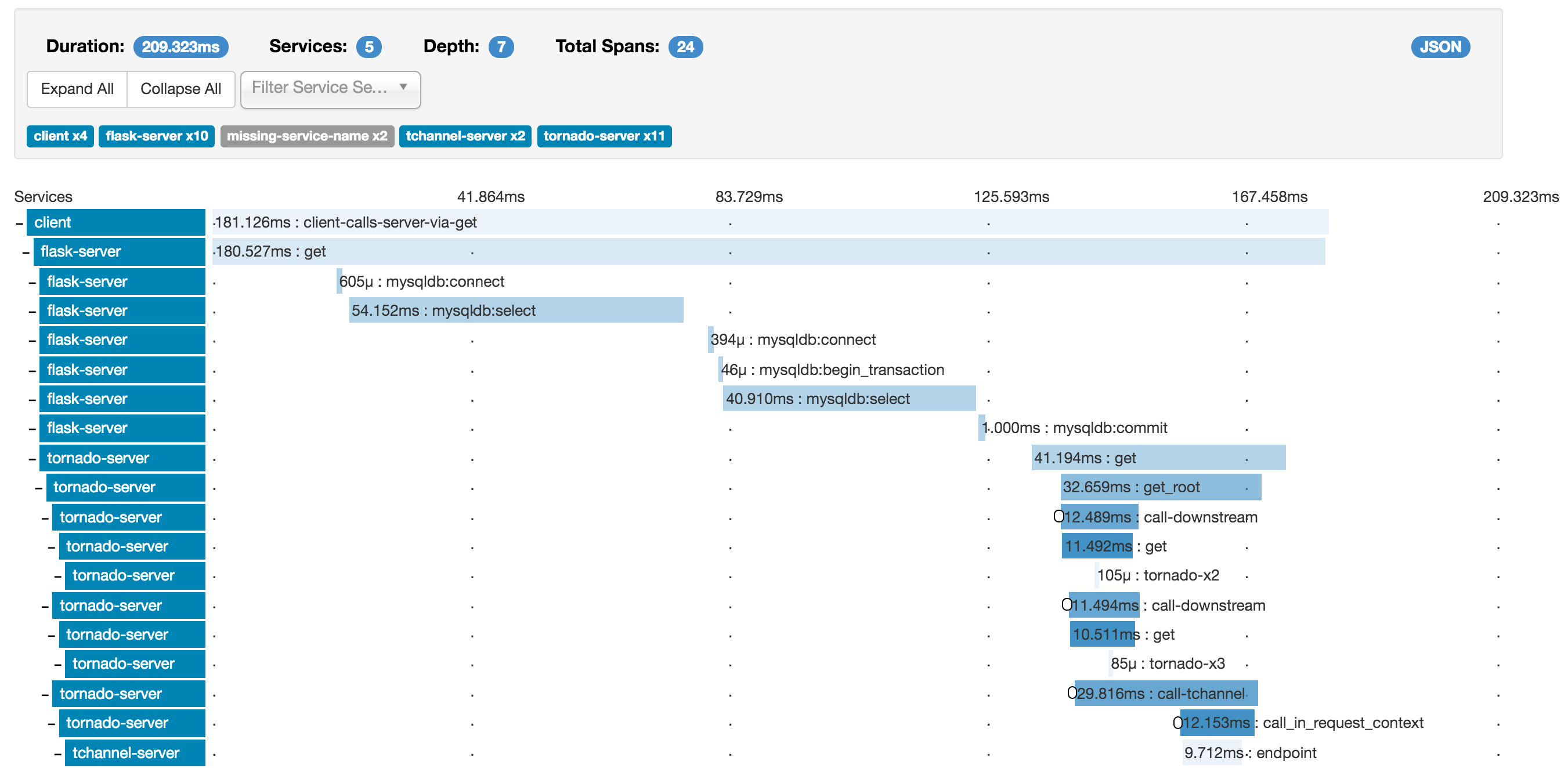
Esta información de traza es remitida por los Reporters al Collector centralizado de Zipkin, que la valida y almacena. Zipkin permite la explotación de esta información mediante una API propia o mediante la UI que ataca a esta API (que puedes ver en la imagen).
Puedes encontrar más detalles de la arquitectura de Zipkin aquí.
Las imágenes de esta entrada se han obtenido del propio proyecto de Zipkin.
Cloudbleed

Cloudbleed es el último incidente de seguridad en la red que presumiblemente puede tener un gran impacto por la información sensible desvelada, tanto en cantidad como en sensibilidad. El fallo fue descubierto el 17 de febrero por Tavis Ormandy, ingeniero de Google que lo reportó a Cloudflare. Cloudflare lo resolvió de manera muy rápida (en menos de una hora cortando los servicios afectados y corrigiéndolos en 7 horas), pero ya ha admitido que el error es posible que existiese desde septiembre de 2016, y lo que es peor, parece ser que ha sido explotado de manera masiva del 13 al 18 de febrero. El problema se hace mayor si se tiene en cuenta que los robots de crawling de los buscadores han estado recuperando y cacheando esta información durante todo este tiempo.
Cloudflare es una compañía de seguridad y servicios para internet, que se ha especializado en lo que se denominan CDN (Content Delivery Networks) enfocados en la seguridad y protección de dominios o servicios de terceros contra ataques, como por ejemplo DoS. Entre las compañías que parece se encuentran afectadas están Uber, OKCupid o Fitbit, entre otras; y sin que se tenga todavía certeza del alcance de los servicios afectados.
El origen del problema se encuentra en el código de los servidores que hacen de proxy inverso con los que Cloudflare realiza toda la actividad de entrega y distribución de los contenidos. Cloudflare no solo se limita a distribuir el contenido, hace transformaciones de manera online como valor añadido o mejoras de seguridad, eficiencia o customización. Existe un componente que adapta o modifica las páginas HTML antes de servirlo. En este código no se comprobaba correctamente si se sobrepasaban los límites de un buffer de memoria al escribir (buffer overrun o buffer overflow), lo que provocaba que la información sensible fuese a las regiones de memoria adyacentes, pero de otros servicios.
Esta información puede contener contraseñas (en claro), cookies e identificadores de sesión, conversaciones de servicios de mensajería… aún cuando los servicios fuesen sobre conexiones seguras, para que nos hagamos una idea del impacto del fallo. Cloudflare ya se ha adelantado a confirmar que las claves SSL privadas (las que autentican a los servicios en la red) no se han visto comprometidas al servirse con un servicio de Nginx no afectado.
Las recomendaciones de los expertos es aprovechar la situación para cambiar y utilizar mejores claves en todos nuestros servicios, en especial aquellos que utilizan los servicios de Cloudflare, y hacer uso siempre que se ofrezca de la autenticación en dos pasos.
Puedes encontrar más información aquí o en el artículo que la propia Cloudflare publicó explicando con todo detalle los aspectos técnicos (un ejercicio de honestidad y detalle de agradecer, asumiendo toda la responsabilidad del error, exculpando a terceros y agradeciendo la ayuda de otros, como el equipo de Project Zero de Google que descubrió y comunicó la vulnerabilidad).
Consejos y buenas prácticas en la gestión de errores: recopilación y comunicación de información

Los errores ocurren y son parte de la fase de servicio del ciclo de vida de toda aplicación. No hay ni que verlos de manera trágica, pues son las singularidades propias de la explotación de la aplicación, ni con excesiva indulgencia, porque son una medida clave de la calidad del servicio que estamos dando.
Pero lo que sí es relevante es que, desde el primer momento de la incidencia, tengamos información suficiente para disparar todos lo mecanismos de análisis y resolución del error. Es necesario que tengamos una recolección de datos automática y eficaz; y esa eficacia sobre todo va a depender, dado lo variado e impredecible de los errores, de lo completos que sean esos datos.
Más importante que la información recopilada para el análisis del problema, es la información y mensajes transmitidos al usuario de la aplicación que sufre el error. Factores como la usabilidad, funcionalidad, gestión del riesgo reputacional o la propia operativa de gestión de incidencias dependen fundamentalmente de este aspecto.
El proceso completo de identificación, clasificación, investigación, resolución y cierre (pasos de la gestión de incidencias según ITIL) es especialmente elaborado y largo como para poder cubrirlo en una sola entrada. Esta entrada pretende solo abordar la primera etapa o paso en la gestión de las incidencias (Identification and Logging según ITIL), y en parte sólo, entrando más en aspectos prácticos que en los formalismos del proceso. El objetivo es cubrir cómo se identifica el incidente, cómo se informa de él y cómo se recopila información que sea útil para su resolución.
La dualidad de actores: usuario y operador
Cuando se produce el incidente hay dos actores interesados o relacionados: por un lado el usuario que no puede resolver de manera normal la operativa, y por otro, el equipo de soporte o de resolución de incidencias que tiene que darle una solución.
Ambos actores necesitan información muy distinta. Por un lado, el usuario no necesita información técnica de qué lo que ha pasado; de hecho, por motivos de seguridad se debería evitar que se revelase o fuese deducible. Por el otro, el soporte debe tener información detallada relativa a la incidencia, pero con un acceso muy limitado y controlado a la propia transacción, si esta tuviese información sensible o confidencial.
Afortunadamente, los canales por lo que se envía la información suelen ser distintos y solo tenemos que tener cuidado en recopilar toda la información necesaria a ambos y mostrar a cada uno la que le corresponde.
No conozco referencias relativas a este asunto, por lo que me he permitido llamar a una la visión del usuario, y a la otra la visión del técnico.
La visión del usuario
Cuando ocurre un error en la aplicación no hay que perder de vista lo más importante: que el usuario estaba intentando hacer algo que podría ser valioso o importante para él. Por eso la visión del usuario (sobre todo cuando estemos hablando de una actividad crítica, relevante o de valor para el usuario o cuando el nivel de calidad de servicio así lo exija) tiene que centrarse en trasmitir muy claramente:
- ¿Qué ha pasado con la operación que estaba haciendo? ¿En qué situación se ha quedado? ¿Qué consecuencias puede tener?
- ¿Qué puedo hacer ahora? ¿Cuáles son los pasos a seguir ahora que estamos en una situación anómala (o no) desde el punto de vista de la experiencia de usuario?
Por otro lado, las formas y el contenido en el que se comunica la información del error y de la situación al usuario es especialmente relevante para la usabilidad de la aplicación. Al ser, el error, una situación excepcional, a veces descuidamos esta usabilidad; pero es justamente esa excepcionalidad, la que nos obliga a tener especial cuidado en los mensajes y cómo se los transmitimos a los usuarios, así como el guiado para que puedan encauzar la operativa. Una buena opción es considerar los errores, al igual que las excepciones en el código, como vías de escape del flujo normal de navegación de la aplicación y considerarlas en su diseño. De esta manera ayudaremos a que en caso de error la aplicación esté en un estado y posición estables y conocidos (la pantalla de error «tal» dentro del proceso funcional «tal») y que sea más usable (el usuario puede utilizar los mismos criterios y flujos de navegación que en el resto de la aplicación).
Información relativa a la operación del usuario
Ya sea escribir un mail, hacer una transferencia o confirmar el pago del carrito de la compra; el usuario está haciendo una operación o transacción importante para él y lo primero de lo que tiene que informarse al usuario es de qué ha pasado con lo que estaba haciendo. Por eso en la información del error que se muestra al usuario se deberían tener en consideración los siguientes puntos:
- Si la transacción se ha finalizado correctamente: ¿se llegó a enviar el mail? ¿se efectúo la transferencia? ¿se ha cobrado en la tarjeta la compra?; o si por el contrario se canceló la operación: el mail no se envió y la transferencia y el pago no se hicieron efectivos
- En cualquier caso, si existe operativa de soporte o ticketing, debe definirse un identificador único que permita al usuario poder identificar su caso. Aunque esa identificación pueda y deba llevarse de manera interna por el procedimiento de soporte, en mi opinión, debe ser comunicada al usuario por motivos de transparencia
- Si la operación no es recuperable, es muy importante indicar al usuario qué va a pasar con la información que ha introducido. Por ejemplo: no he podido finalizar mi compra pero he introducido información sensible como es mi dirección o mi tarjeta. En este caso es conveniente:
- Informar al usuario de qué información va a almacenarse y de cuál se va a eliminar
- Indicar qué criterios se utilizarán para gestionarla. Como puede ser el almacenar dicha información por 30 días por si es necesaria para el equipo de soporte, por ejemplo
- Si estamos obligados por imperativo legal o de cualquier otro tipo a mantenerla, no está de más mencionar estas exigencias u obligaciones
- Informar al usuario de cómo puede verificar y eliminar esos datos. Desde su perfil o poniéndose en contacto con nosotros, por ejemplo
Pasos a tomar y opciones de resolución
Ahora que el usuario tiene ya una idea clara de qué ha pasado con su operación, es necesario indicarle cómo puede completar dicha operación
- Si no quedó claro o no se pudo verificar el estado en que quedó la operación, debemos informar al usuario de cómo puede verificar la operación o dónde o con quién puede ponerse en contacto, como puede ser el equipo de soporte
- Si tenemos cierta certeza de que el fallo es transitorio, podemos invitar a reintentar la operación al usuario pasado un tiempo o cuando podamos contrastar que el problema ha remitido
- Si es posible continuar la operación o recuperarla en un punto en concreto, debemos indicar al usuario cómo y cuándo (más tarde por mail, por ejemplo) hacerlo; facilitando lo máximo posible este reintento y evitando todo lo posible la repetición de pasos ya realizados. Este punto es importante por varios motivos estratégicos:
- Porque mejoramos el servicio y funcionalidad ofrecida al usuario y con ello la percepción que tiene de nuestro producto y reducimos el daño reputacional del error
- Porque evitamos el tedioso proceso de repetir toda la transacción mejorando la experiencia de usuario
- Porque reducimos el impacto del fallo o caída de servicio habilitando el que de los servicios perdidos algunos se puedan recuperar
- Porque evitamos que parte de los usuarios afectados migren a la competencia buscando el mismo servicio
- En la medida de lo posible debe ser parte del flujo normal de navegación y seguir los mismos criterios de navegación, forma y contenido de la información que en el resto de la aplicación. Esto transmite la sensación de ser un situación controlada al usuario, con lo que se limita la pérdida reputacional y se atenúa la sensación de gravedad; además de facilitar el guiado para la resolución del problema.
La visión del técnico
Los mecanismos de log pueden ser de gran ayuda, y son el referente normal en estos casos; pero para que puedan ser manejables desde el punto de vista operativo, suelen ser muy poco detallados. Lo singular e infrecuente del error nos permite que la recolección de información de incidencias pueda ser mucho más exhaustiva, elaborada y detallada. Esta información de mucho más volumen, pero de menor frecuencia.
Es muy importante recordar que esta información es altamente sensible y que su divulgación podría desvelar vulnerabilidades y patrones de ataque. De hecho, una parte fundamental que precede a los ataques informáticos, es el análisis de estas vulnerabilidades. El forzar situaciones de error puede permitir, si no se controla con cuidado, que se pueda obtener información muy sensible y relevante, vulnerabilidad, para luego poder ser explotada.
El siguiente es un checklist de información que puede ser útil recopilar para la visión del técnico:
- Entorno
- Hora y fecha
- Posición geográfica, en especial en entornos móviles o distribuidos
- Conectividad, también cobra especial importancia en entornos móviles
- Host o instancia de máquina, para entornos distribuidos
- Servicio o contenedor de la aplicación
- Hebra o proceso del sistema operativo
- Paths y parámetros de configuración del servicio
- Cliente
- Navegador, a través de las cabeceras HTTP o recopilando esa información desde la ejecución de código en el mismo navegador
- Dispositivo, sea un móvil, equipo informático clásico, smartwatch, sistema empotrado…
- Periféricos de los que hagamos uso
- Usuario
- Parametrizacion o personalización del usuario
- Idioma, zona horaria y configuración regional
- Credenciales, roles y autorizaciones
- Transacción
- Tipo de operación
- Parámetros de la operación
- Estado actual de la transacción
- Aplicación
- Componente software en el que se produjo el error o salida del flujo normal de ejecución
- Stack trace de ejecución con los parámetros en el flujo de llamada
- Variables de estado, de sesión, de ejecución, volcados de memoria, registros del micro…
Hay que tener especial cuidado cuando la información recabada sea relativa a sistemas que no son de nuestra propiedad y que lo puedan ser del usuario, como por ejemplo: la información del propio equipo del usuario, de su móvil o la obtenida relativa al navegador. En este caso, es ético y recomendable informar al usuario de qué información se obtiene de una manera explícita y concreta (aunque sin ser apabullante con detalles). Mejor si le permitimos, incluso, decidir si quiere compartirla con nosotros o no.
Referencias
La foto de cabecera ha sido tomada de https://www.flickr.com/photos/sissou/8432968631 y se está usando bajo licencia CC.

Esta entrada de Juan Francisco Adame Lorite está publicada bajo una licencia Creative Commons Atribución-CompartirIgual 3.0 Unported.
Apache Kafka
![]()
Apache Kafka es un sistema de procesado de mensajes. Los mensajes se publican por los productores (producers) en colas denominadas topics y se consumen de la cola por los consumidores (consumers) suscritos a dicha cola. Es una solución al problema de los productores-consumidores concurrentes. En este problema existen uno o más actores (productores) que generan los mensajes que son procesados por uno o más actores (consumidores) de manera concurrente.
El sistema de encolado y procesado de mensajes es distribuido y particionado en diferentes instancias denominadas brokers que conforman el clúster de Kafka. Dentro del clúster, en cada broker, cada topic o cola está dividida en particiones en las que los mensajes se almacenan de manera secuencial. Las particiones de un topic permiten:
- Distribuir la carga de trabajo entre diferentes brokers y consumidores
- Tener tolerancia a errores de los brokers, al poder tener replicadas la misma partición en brokers distintos (aunque solo una es la activa, pueden tomar el sitio de la activa si ésta cae)

El productor es quien encola los mensajes en cada partición, que mantiene estos mensajes de manera secuencial y ordenada. Es el propio productor quien decide en qué partición específica del topic se almacena el mensaje. De esta manera el balanceado de los mensajes en las diferentes particiones queda en manos del productor, no del clúster, que puede basarse en criterios de balanceado de carga o de lógica de negocio.
El modo en que se distribuyen los mensajes a los consumidores es también bastante flexible. Los consumidores se agrupan en grupos de consumidores. El clúster distribuye los mensajes de cada partición a un único consumidor del grupo, pero si hubiese más de un grupo de consumidores lo haría para cada grupo. De esta manera nos encontramos en un cola clásica con la carga balanceada entre varios consumidores si solo hay un grupo, y en un modelo de suscripción si tuviésemos más de un grupo.

El único modo de garantizar que los mensajes se consumen en el orden en que se crean es teniendo una única partición por topic y un solo consumidor por grupo. El único modo de garantizar que los mensajes se consumen una sola vez es teniendo un único grupo de consumidores.
El consumidor de cada partición es el que decide el orden en que se procesan los mensajes y los mensajes que se procesan. El consumidor tiene libertad para moverse en la partición accediendo a los mensajes de manera indexada (offset desde comienzo) y en sentido y con el criterio que quiera, y es quién lleva constancia de si han sido consumidos o no. Esto permite que la política o lógica de procesado de mensajes sea mucho más flexible que la cola tradicional, permitiendo el reprocesado de mensajes, el procesado en cualquier orden o el consumo de mensajes en la misma partición por diferentes consumidores (si están en distintos grupos).
Los mensajes se mantienen en la partición, con independencia de si han sido consumidos o no, durante el tiempo indicado por la política de retención de mensajes. No hay borrado de los mensajes. Esto se debe a una decisión de diseño muy eficiente, puesto que el acceso al disco secundario es siempre secuencial y no aleatorio, con las ventajas de rendimiento que supone.
Mi opinión es que Apache Kafka es un solución muy versátil y sencilla para consumir o transformar elementos de información que se generan a un ritmo no constante o mantenido, sino poissoniano, como son eventos, mensajes, peticiones… Siguiendo la documentación, que por cierto es muy buena y completa, los ejemplos de aplicación más comunes son como sistema de mensajería tradicional, monitor de actividad web o monitor de métrica de operaciones, agregador de log, gestor de eventos, procesador de streams de datos…
![]()
Apache ZooKeeper

Apache ZooKeeper es un servicio de datos en estructura de árbol. El servicio es centralizado, replicado, de alta disponibilidad y escalable; y garantiza la integridad en accesos concurrentes y el orden de modificación de los datos de manera secuencial. El sistema está formado por un conjunto distribuido de instancias denominado quorum que sirven la misma información.
El servicio es centralizado porque solo una de las instancias en ejecución hace las veces de instancia maestra, es la única que puede modificar los datos y que los replica al resto de las instancias. Esto garantiza el orden de los cambios, la atomicidad transaccional y la integridad concurrente de la información. Cuando la instancia maestra cae, el algoritmo de elección de líder, decide qué instancia es la nueva instancia maestra. El acceso de lectura, sin embargo, puede hacerse a cualquiera de las instancias levantadas del sistema. Esto por un lado garantiza la disponibilidad, al poder cualquier nodo convertirse en líder, y el rendimiento y la escabilidad, al permitir poder añadir todas las instancias que queramos al quorum para repartir la carga. Este diseño lo hace más adecuado para situaciones en que la lectura de datos es mucho más habitual que la escritura (al menos 1:10 según la documentación).
El servicio es rápido porque los datos se encuentran en memoria de cada instancia y solo se replican a disco para garantizar su persistencia. También es muy sencillo, tanto en el modo en que almacena la información; como en el modo en que se accede a la misma, con un conjunto de operaciones que son muy básicas y reducidas en número.
La forma en que se estructuran, organizan y acceden los conjuntos de datos es en estructura de árbol. Muy parecido a lo que sería un sistema de ficheros clásico pero siendo todos los nodos iguales, sin que haya distinción entre directorios y ficheros: todos los nodos son accesibles, pueden contener datos y pueden tener nodos hijos. Cada nodo puede contener cualquier tipo de información ya que el acceso es binario, pero el sistema está diseñado para que sean de un tamaño moderado, unos pocos kilobytes como mucho.
Los clientes tienen configuradas una o varias de las instancias del quorum, que no tienen por qué ser todas los integrantes, y que son los que se encargan de presentar al cliente al líder en ese momento.
Los usos más habituales de este servicio es como repositorio de información de configuración y nombres, o para proveer mecanismos de sincronización (lock, mutex,…) para soluciones distribuidas.
Un ejemplo de uso que me parece muy apropiado puede ser como repositorio de configuración de un conjunto de componentes muy numeroso, por ejemplo los sistemas de red de una gran organización o los diferentes servicios de una granja de servidores. Cada nodo hoja de la estructura de árbol puede ser un sistema o servicio y la información que contiene su configuración o estado. Los nodos rama nos permiten organizar, agrupar y clasificar los sistemas o servicios de la manera más adecuada para la organización. La configuración de todos los sistemas o servicios se gestiona de manera centralizada (solo hay una configuración aún estando replicada), la solución es muy escalable y tiene alta disponibilidad (levantando más instancias podemos servir a más clientes) y es también deslocalizable (al permitir desplegar instancias en diferentes lugares buscando la idoneidad específica para cada cliente).
Es también común verla como mecanismo de sincronización o como monitor de soluciones distribuidas como en Druid, por ejemplo.
![]()
Docker

Docker es una plataforma para la virtualización de entornos a nivel de aplicación o software base en lugar de sistema operativo o máquina virtual. Docker permite definir las diferentes unidades de despliegue de la solución software, con sus componentes distribuidos y sus límites de interconexión con otras unidades, para permitir su despliegue apilado de tal manera que representen las diferentes capas de las soluciones.
La idea es que, en lugar de crear una máquina virtual completa para cada entorno con sus recursos virtuales y sistema operativo, sea el propio sistema operativo el que aísle y compartimente la ejecución de cada entorno, denominado container. El propio sistema operativo crea un entorno de ejecución aislado a nivel de sistema de ficheros, de red, de seguridad y ejecución; de tal manera que los diferentes entornos, aún ejecutando en el mismo sistema operativo, están aislados entre ellos o solo compartiendo aquellas partes que se deseen.
Docker para implementar su funcionalidad se basa en dos características del kernel de Linux, cgroups y namespaces, que permiten establecer criterios de prioridad de CPU, limitación de memoria o de operaciones de I/O o control de facturación en el primer caso; o aislar procesos, entornos de red, usuarios, sistemas de ficheros entre los diferentes entornos en el segundo.
Cada entorno en Docker en ejecución es un container, que se corresponde con el despliegue de una imagen, que contiene la definición del entorno, sus límites, puntos de interconexión con terceros y componentes software. Los containers pueden apilarse de tal manera que cada uno represente una capa de la solución final. La combinación apilada de containers se produce mediante la definición de los puntos de interconexión de los container, como pueden ser puertos de red, y la sobreposición de los sistemas de ficheros uno sobre otro, mediante UnionFS.
La posibilidad de dividir los diferentes componentes distribuidos y capas del aplicativo en diferentes containers apilables supone una gran ventaja tanto para desarrolladores como para técnicos de explotación. Por un lado las dependencias se resuelven dentro de los propios container de la solución por lo que dentro de un mismo sistema no hay incompatibilidades entre versiones y dependencias. Por otro, el proceso de despligue se modulariza y la nivelación de entornos de integración y productivos es mucho más sencilla, al basarse en el despliegue secuencial de estas unidades.
Las imágenes que se despliegan como containers pueden registrarse en directorios públicos o privados (dentro del ámbito de la organización) con Docker Hub. El servicio en la nube que registra, almacena, distribuye y da soporte social y colaborativo a la tarea de gestión de las diferentes imágenes. Este es el servicio que monetiza toda la idea. Secundo la opinión de D’Oh de que puede ser una excelente alternativa o mecanismo en el que basarse las futuras tiendas de aplicaciones o sistemas de paquetes de los sistemas operativos.
Aunque la tecnología está basada en características propias de Linux, existen versiones portadas a Windows o iOS, pero con un componente adicional de virtualización para dar soporte a estas funcionalidades de compartimentación que no existen, al menos de manera idéntica, en estos sistemas. Las plataformas de virtualización en la nube Amazon EC2 y Google Cloud también soportan de manera nativa Docker.
«Best and bad practices» del desarrollo software
Leemos en Microsiervos un artículo de Yacoset, que aún teniendo un cierto tono de humor, me resulta muy interesante y completo respecto a los do y don’t a la hora de desarrollar:
Por un lado tenemos los síntomas que podemos observar cuando desarrollemos mal:
Signs that you’re a bad programmer
Y por otro lado, los signos que aprueban nuestro trabajo:
Signs that you’re a good programmer
Muy recomendable.
gRPC y Proto 3
Google hace público el protocolo o mecanismo RPC que utiliza en alguno de sus sistemas, gRPC:
https://github.com/grpc/grpc-common
Para el envío de mensajes utiliza el protocolo Protocols Buffers en su versión 3:
https://github.com/google/protobuf
Google asegura que son ligeras, rápidas y muy eficientes en cuanto al consumo de recursos. La verdad es que los ejemplos aparentan que es muy sencillo integrarlo.
Ambas opciones son multilenguaje/multiframework soportando C++, Java, Python, Go y Ruby entre otros (incluyendo la posibilidad de invocarse entre plataformas distintas). Pero sobre todo me llama la atención la opción de Android, porque hace tiempo buscando soluciones para RPC en este entorno no encontré ni muchas opciones, ni muy buenas.
Checklist de requisitos no funcionales

La presente entrada pretende ser un pequeño recopilatorio o lista de control de requisitos no funcionales. No es una entrada definitiva, y de hecho la idea es que vaya creciendo y actualizándose con el tiempo. Invito a todo el que quiera a que aporte correcciones, añadidos y observaciones.
Aunque me gustaría que fuese completa, no pretendo que sea exhaustiva. En las diferentes áreas y aspectos existen grupos de trabajo, estándares y procedimientos suficientemente completos si se quiere profundizar. Por ejemplo, el apartado de la seguridad, por su propia sensibilidad, está muy trabajado en este sentido y existen estándares como el ISO 27002 o la iniciativa OWASP que contienen checklists y mecanismos de certificación muy completos y detallados. De igual manera, algunos aspectos como Usabilidad son especialmente ambiguos y poco detallados debido a mi falta de experiencia en ellos.
Requisitos
Un requisito es una propiedad física o funcional de un sistema o solución que representa la necesidad, con sus restricciones y detalles, que debe cumplir por diseño, para que cumpla el fin o utilidad con el que fue creado. Es, junto con el alcance, lo que nos dice «qué tiene que hacer y cómo» nuestra solución para que sea útil y tenga valor.
Si nos ceñimos a la norma ISO/IEC/IEEE 29148:2011 los requisitos deben ser:
- Necesarios. Deben definir una capacidad, característica o restricción sin la cuál el objeto del proyecto o producto sería incompleto. Aunque también pueden documentarse como opcional, deseables, negociables…
- De libre implementación. Aún siendo suficientemente completo su definición debería ser completamente independiente del modo en que se implemente. En la medida que independicemos la fase de diseño de la de análisis, daremos más libertad a la implementación y obtendremos un mejor producto.
- Unívocos. Que su definición solo pueda interpretarse de una única manera.
- Consistentes. Que no entren en conflicto con otros requisitos.
- Completos. Describe de manera completa, sin deficiencias ni necesidad adicional de información, el requisito. También es necesario especificar el nivel y alcance del requisito, no es lo mismo que el sistema por diseño sea capaz de cumplir el requisito, que verificar de manera continuada y rigurosa que el requisito se cumple durante la explotación del sistema.
- Singulares. La definición incluye un único requisito. Lo que luego nos puede ayudar a auditar y validar cada requisito de manera única y sencilla.
- Posibles. Que sean técnicamente posibles, dentro de las restricciones propias del proyecto. Esto incluye que sean posibles bajo los análisis de riesgo o coste-beneficio.
- Referenciable. Que pueda ser referenciado o identificado de manera única, ordenada y estructurada. Que tenga una codificación correcta y unívoca.
- Verificables. Que existan mecanismos que permitan verificar que realmente el requisito se cumple y criterios definidos para validarlo
Aunque me gustaría también añadir una propiedad que se mencionaba en el estándar original de esta norma (IEEE 830)
- Modificable/gestionable. Que existan mecanismos para, cuando sea necesario y dentro de los procedimientos y formalismos establecidos para la gestión del producto o proyecto, poder modificar la definición del requisito, su eliminación o la inclusión de nuevos requisitos siguiendo los criterios anteriores.
Los requisitos pueden ser funcionales o no funcionales:
- Funcionales. Hacen referencia a funciones o resultados esperados del sistema, enfocados en resolver el problema o la operativa para el que fueron creados. Responden a la pregunta de qué debe hacer el sistema.
- No funcionales. Hacen referencia a detalles, aspectos, atributos o propiedades del sistema enfocados en cómo se debe resolver el problema o la operativa objeto del sistema. Responden a la pregunta de cómo lo debe hacer el sistema.
Se podría decir que los requisitos funcionales representan la parte del mundo real que toca al sistema y los no funcionales la parte tecnológica.
El análisis completo de los requisitos funcionales es relativamente sencillo. Si se nos pasa alguno, es muy seguro que estemos olvidando una funcionalidad relevante del sistema. Los cambios, añadidos y eliminaciones de requisitos funcionales suelen tener impacto en el alcance del proyecto. Además, son aquellos donde el usuario o los no especialistas en tecnología aportan mucho más, siendo el feedback practicamente suyo por completo.
Sin embargo, hacer un análisis completo de los requisitos no funcionales es más complicado. Primero, porque los actores que más feedback pueden dar en el análisis de los requisitos no funcionales son necesariamente aquellos con conocimientos técnicos; y normalmente no están en el conjunto de actores que conocen la naturaleza del problema, sino en el de los analistas.
En segundo lugar y más importante, porque se confunden con facilidad con decisiones propias del diseño. Algo, que aparentemente, parece una restricción o exigencia técnica, es solamente un efecto de una decisión de diseño tomada, y su obligación se debe a la vinculación con este diseño. Si cambiamos el diseño, muy posiblemente el requisito cambie o pierda consistencia. Si un requisito no funcional puede cambiarse por otro o cambia si cambiamos el diseño, es muy probable que estemos hablando de una consecuencia del diseño de la solución, y no de un requisito como tal. Este aspecto es importante, porque los requisitos no deben condicionar la implementación (solo su resultado o producto). Por eso, el exceso de definición en este aspecto, no es todo lo beneficioso que pensamos.
Desgraciadamente un requisito no funcional pasado por alto puede tener efectos catastróficos en un diseño o implementación ya iniciados. Esta lista, como checklist que es, tiene como único objetivo facilitar que el análisis de requisitos sea completo y evitar que se nos pase por alto algún aspecto que podría ser útil a nuestro análisis. La gran mayoría de los requisitos de esta lista no van a aplicar ni tener sentido para el problema que estemos analizando, pero lo importante es que no se nos pase aquel requisito que sí es relevante, beneficioso o imprescindible.
Por último, el conjunto de los requisitos no funcionales tienen unos efectos en el reparto de la carga de trabajo de implementación que, por lo general, son mayores que el de los requisitos funcionales. Cada diferente requisito no funcional debe abordarse como una solución separada, heterogénea y poco acoplada con las de otros requisitos, con las consecuencias que esto tiene en el desempeño y en la curva de aprendizaje. Las plataformas más generalizadas como son Java o Microsoft .net, han infravalorado este aspecto de manera habitual. En Java suelen ser implementados por librerías de terceros, que aveces tienen su clon en versiones oficiales posteriores de la plataforma; en el caso de .net, es común que cambien bastante de versión en versión. Nuevas plataformas como Django o Ruby on Rails, se centran precisamente en la reusabilidad del código relativo estos requisitos con bastante acierto, facilitando y focalizando el trabajo del desarrollador en lo funcional.
Checklist
- Seguridad
- Seguridad física tanto de los sistemas como los medios de almacenamiento, líneas de comunicación, copias de respaldo.
- Cifrado de datos, tanto en las comunicaciones, como medios de almacenamiento, copias de respaldo.
- Auditabilidad, qué información y mecanismos existen para revisar la operativa de la solución, qué mecanismos garantizan la fiabilidad e integridad de esa información.
- Control de acceso, cómo se autentican los usuarios, cuál es el modelo de autorización, cuál es el ciclo de vida de las credenciales y sesiones
- Qué información está disponible en el acceso anónimo, qué damos a conocer de la organización, cómo protegemos nuestros sistemas del fingerprinting
- Cómo protegemos la integridad de la información, cómo validamos que sea correcta, cómo impedimos su manipulación no autorizada
- Cómo se gestionan los errores para que sean siempre controlados y no desvelen información no autorizada
- Cómo impedimos la operativa no autorizada, cómo protegemos la manipulación de peticiones o servicios qué información es insertable mediante formularios, servicios o uploads de ficheros
- Cómo se van a gestionar los incidentes de seguridad
- Si nos vamos a ceñir a algún tipo de guía de seguridad o si va a ser necesario certificar el sistema contra algún estándar u obligación legal, bien por criterios de calidad o por exigencia externa
- Capacidad y Escalabilidad
- Qué niveles de rendimiento se necesitan:
- Nivel mínimo aceptable para no mermar la experiencia de usuario
- Número de usuarios concurrentes
- Operaciones o transacciones por unidad de tiempo
- Qué niveles de capacidad se necesitan:
- Requisitos de memoria principal
- Requisitos de memoria secundaria, terciaria y offline
- Cachés de memoria intermedios
- Requisitos de capacidad de la copia de respaldo
- Tamaños de colas de mensajes y de servidores antes del desbordamiento o descarte de la petición
- Número máximo de peticiones concurrentes por servicio
- Si el sistema debe estar preparado para la escalabilidad vertical (más recursos por nodo) u horizontal (más nodos simultáneos por nivel)
- Plan de capacidad o cómo se espera que evolucionen los requisitos anteriores con el tiempo
- Qué niveles de rendimiento se necesitan:
- Disponibilidad
- Qué componentes están replicados de manera activa o pasiva
- Ciclo de vida de la información
- Cómo discurre la información desde que se procesa hasta que se almacena en la copia de respaldo
- En qué componentes se almacena de forma persistente y en cuáles volátil
- Dónde se pueden introducir sondas para extraer información, bajo qué criterios o restricciones
- Cómo y cuándo se historifica la información, cómo se borra, soft-delete (marcado del registro como borrado) o hard-delete (borrado físico de la información)
- Qué estados de la información pueden considerarse estables o coherentes (¿un rollback destruye la transacción o la devuelve a un punto estable intermedio anterior?)
- Cuál es el nivel de detalle o de precisión de la información
- Si las operaciones y servicios son idempotentes o puras
- La copia de respaldo:
- Qué contiene la copia de respaldo
- Cuál es el punto de recuperación objetivo
- Cuál es el tiempo de recuperación objetivo
- Cómo se cifra la copia de respaldo
- Cómo se almacena de modo ordenado y seguro
- Cómo se recupera dicha información
- Cómo se destruye
- Plan de continuidad
- Ante una caída de servicio cómo se espera continuar la actividad sin el sistema
- Cuál es el tiempo máximo admisible de esta caída o cómo afecta a la actividad en función de este tiempo
- Plan de recuperación
- Ante una caída de servicio cómo se espera recuperar el sistema para que dé servicio
- Cuál es el tiempo de recuperación estimado
- Mantenibilidad
- Qué arquitectura, framework, infraestructura de hardware o software base
- Qué metodologías de trabajo
- Qué estándares de codificación, nomenclaturas o convenciones
- Qué herramientas de ciclo de vida de producto, de construcción del producto, de integración continua o de chequeo de software
- Qué sistemas de versionado y nombrado de versiones, así como las políticas de versionado
- Qué políticas de adopción/integración de librerías y de software de terceros
- Qué políticas de gestión y configuración de entornos, qué políticas de gestión del cambio
- Cómo se gestionan de logs y trazas y con qué herramientas
- Qué políticas, procedimientos y herramientas de gestión de incidencias
- Qué documentación se va a generar y en qué formato
- Qué indicadores o estadísticas se monitorizan para conocer el estado o salud del sistema
- Ciclo de vida
- Cómo se despliega/repliega
- Cómo se realizan las intervenciones o paradas del sistema
- Cómo se realizan el upgrade de componentes, así como de los datos y parametrizaciones del aplicativo
- Robustez y estabilidad
- Cómo se gestionan los errores del sistema
- qué información muestran al usuario
- cómo se informa al usuario de la situación actual de su transacción y de cuáles son los siguientes pasos a seguir
- qué información almacenan para la identificación y el análisis del error
- Cómo se recupera el sistema de los errores, cómo vuelve a un punto estable parcial (punto de recuperación intermedio) o total
- Cómo se gestionan los bugs desde su descubrimiento hasta su resolución, cómo se incluyen en las pruebas de regresión del sistema
- Cómo se gestionan los errores del sistema
- Integridad y Consistencia
- Qué es una transacción, qué componentes comprende, cuál es su alcance
- Si se permiten faltas de sincronismo en la replicación de la información entre componentes (porque tarda en llegar de uno a otro) o de integridad (porque se permiten inconsistencias entre componentes)
- Qué controles de integridad y coherencia de datos
- Integración
- Qué interfaces se definen con otras aplicaciones, de qué tipo
- Qué componentes ya existentes en la organización se utilizan, cuál es la política de reusabilidad
- Cómo de divide en módulos diferenciados, cómo se integran entre sí
- Configuración
- Cómo se configura y parametriza
- Qué es parametrizable
- Cuál es el alcance de cada parámetro: del sistema, por entorno, por usuario, por región…
- Cuáles son los valores por defecto
- Internacionalización
- Cómo se soporta el uso de múltiples idiomas, qué idiomas se soportan, cómo se traduce la solución a otros idiomas
- Cómo se parametrizan los diferentes aspectos regionales de formato numérico, fechas, aspecto…
- Cómo se soportan las zonas y usos horarios, cómo se gestionan los cambios de horario, qué convenciones tiempo se utilizan
- Portabilidad
- Es necesario portar la solución a más de un entorno de ejecución o plataforma
- Legales
- Cuál es la licencia o condiciones de uso de la aplicación
- Cuáles son y cómo afectan las licencias y condiciones de uso del software de terceros
- Qué requisitos o exigencias legales deben tenerse en cuenta
- Operación
- Qué conjunto de operaciones o catálogo de servicios es necesario
- Cómo trabajan o que interfaz utilizan los operadores con la solución
- Qué requisitos técnicos necesitan los operadores
- Cómo se forma a operadores
- Qué nivel de demanda o disponibilidad de operadores requiere la operación de la solución
- Cómo y hasta qué nivel se automatizan las operaciones
- Usabilidad
- Navegabilidad
- Cuál es el mapa de navegación
- Cuáles son los criterios de navegación (adelante, atrás, histórico, menus, error…)
- Cómo se indica en todo momento en qué lugar nos encontramos
- Ayuda en pantalla
- Cuál es el nivel de detalle de esa ayuda
- Cuál es la terminología utilizada
- Cómo se referencia a las diferentes partes del manual o documentación
- Aspecto
- Colores, fuentes y maquetación
- Cómo se usan para que estén acorde al sentido o significado de lo que muestran
- Guía corporativa de diseño y estilo
- Cómo se adapta el interfaz a dispositivos con poco tamaño o monocromo
- Contenido
- Cómo se maqueta y distribuye
- Cómo es de legible el texto
- Cómo se introducen y validan valores y formularios
- De dónde se pueden obtener imágenes (banco corporativo de imágenes)
- Colores, fuentes y maquetación
- Responsible design
- Cómo se adecua, transforma y maqueta el contenido en los diferentes dispositivos y tamaños
- Qué estándares de formateado o visualización se siguen
- Qué cliente se utiliza
- Qué navegadores son soportados
- Usabilidad
- Cuál es el glosario de términos y comandos
- Cómo se informa al usuario del estado actual de su operación:
- En espera o ejecutando una acción, del estado de dicha operación y del tiempo estimado de espera
- En la llegada de eventos
- Del resultado de una operación
- Cómo se avisa de errores, alertas y se solicitan confirmaciones
- Cómo se adapta el UI para mostrar las opciones posibles
- Cómo se definen los atajos y el uso del teclado
- Cómo se define el uso del ratón o de un dispositivo multitáctil
- Cómo se habilita el deshacer/rehacer de operaciones, cómo se gestiona ese default
- Navegabilidad
Referencias
http://thoughts-agile.blogspot.com.es/2013/09/non-functional-requirements.html
http://www.eyefodder.com/2011/06/quality-software-non-functional-requirements.html

